Arthur Tétaz¶
Stage de deux mois en électrophysiologie des plantes sur le projet Plantes connectées du 20/04/2026 au 19/06/2026. En raison de l’ampleur et de la pluridisciplinarité du projet, les travaux réalisés au cours de ce stage se sont principalement concentrés sur la partie électrophysiologie végétale (avec l’acquisition des signaux au moyen de capteurs placés sur la plante ainsi que leur traitement) et la partie conception et entraînement d’un réseau de neurones artificiels. Le but est d'appliquer des méthodes de classification de signaux EGG (électroencéphalogramme d'humain) à l'électrophysiologie végétale. A la fin de mon stage, nous avons discriminé les phases biologiques de la plante (jour et nuit) grâce au réseau de neurones (mais il n'arrive pas à généraliser l'apprentissage).
- Contenu
- Arthur Tétaz
Plan général du projet (cadre théorique)¶
1- Capter les signaux¶
Grâce au capteur Capteur_Vegetal_signals, nous allons utiliser 4 capteurs pour une plante qui serait au soleil et 4 capteurs pour une plante qui serait à l'ombre (ou bien carrément prendre 4 plantes et mettre 2 capteurs sur chacune). Au début, nous préférons simplifier les choses en faisant l'expérience avec du soleil en extérieur et mettre une plante dans une boîte pour la priver du soleil.
2- Visualiser les signaux en temps réel¶
Cette étape est pédagogique. Nous pouvons utiliser le logiciel Chataigne pour visualiser en temps réel les signaux des plantes.
3- Traiter les signaux¶
Il faut séparer cette étape en deux : d'abord acquérir les signaux des plantes puis les traiter ensuite. Nous avons vu en premier lieu les données de Quentin Perret, mais il semble à ce jour qu'il y a un problème avec la transformée de Fourier (TDF) car elle affiche seulement un pic à 0.
4- Entraîner les données¶
Tout d'abord, il faut réfléchir à l'architecture du modèle d'IA qui serait le plus adapté (modèle U-Net, random forest ou bien des réseaux de convolution type CNN). Ensuite choisir le bon framework entre PyTorch, Keras et TersorFlow (même si nous sommes plus partis sur PyTorch pour son aspect open source). Enfin, analyser le signal en Deeplearning. C'est-à-dire quelles méthodes peut-on utiliser et quelles sont les pipeline qui sont utilisées.
Note : ne pas oublier l'étape de normalisation dans le traitement.
5- Faire bouger le robot¶
Puisque le robot chenille n'est pas fonctionnel pour le moment, il faut d'abord se focaliser sur le robot axial, qui fait tourner le pot sur un seul axe. Pour ensuite, pourquoi pas, utiliser un plateau roulant ou un robot avec roue holonome (qu'on emprunterait à Rhoban) à utiliser en extérieur ou dans le Fablab.
6- Faire une interface utilisateur¶
Pour finaliser le projet et le présenter.
Au vu de mes 2 mois de stage, nous nous sommes préoccupés du traitement du signal ainsi que l'entraînement des données.
Installation de l'expérience¶
Voici notre installation sur les plantes Monstera Deliciosa, deux plantes dans deux pots différents qui se sont rejointes (attention car nous appris cela après avoir dit que ce n'était qu'une seule plante dans mon mémoire) : 
Et voici le tableau regroupant la position des capteurs sur la plante, ainsi que leurs numéros associés (avec les capteurs 2 et 8 témoins grisés) :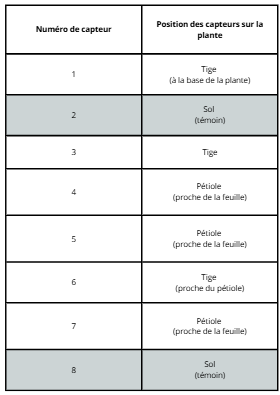
Partie construction et entraînement d'un réseau de neurones¶
Sur la base de l'article de Lawhern et ses collaborateurs, avec un CNN compact écrit avec la bibliothèque python Keras de TensorFlow. Mais nous avons repris la base de ce code Github écrit en PyTorch. Au lieu d'entraîner le modèle sur un jeu de données aléatoires, comme fait dans le code PyTorch, nous l'avons entraîné sur le jeu de données EEG de Bonn téléchargé sur la plateforme Kaggle. Voici le détail du jeu de données :- O et Z = set A et B sur l'article, respectivement les mesures yeux ouverts et jeux fermés pour des individus neurotypiques
- F et N = set C et D sur l'article, respectivement les mesures des zones épileptogènes pendant une période sans crise et prélevées dans l'hippocampe de l’hémisphère opposé chez les patients épileptiques
- S = set E sur l'article, mesures d'une crise épileptique chez les patients épileptiques.
Ensuite, on a repris la partie du script qu'on avait laissé sur la création de données aléatoire pour faire la transformation en tensor. La transformation permet de nettoyer (en enlevant le bruit), de normaliser (mettre tout sur la même échelle) et mettre en forme (adapter le signal à l'architecture).
Nous avons donc créé le modèle, fait la partie training et load (charger les données), mis les data en les mettant dans des listes puis mis les listes dans le même format que celles créées de façon random pour le modèle.
Une erreur rencontrée lors de la construction du modèle est la suivante :
RuntimeError: mat1 and mat2 shapes cannot be multiplied (16x2880 and 3072x5)
En premier lieu nous avons pensé que cette erreur était due à la fonction d'activation utilisée dans les couches denses (hidden layers) du réseau. J'ai donc changé la fonction ELU par Tanh mais rien ne changeait. L'autre possibilité venait de cette ligne dans le script du modèle EEGNet :
self.Dense = nn.Linear(F2*round(signal_length/32), num_class)J'ai donc changé le premier argument en mettant 2880 (pour avoir la même taille que la matrice attendue), sans changer le deuxième argument (num_class = 5).
Ca fonctionne bien, le modèle s'entraîne ! Avec 50 époques, on obtient ce graphe avec la fonction d'activation Tanh :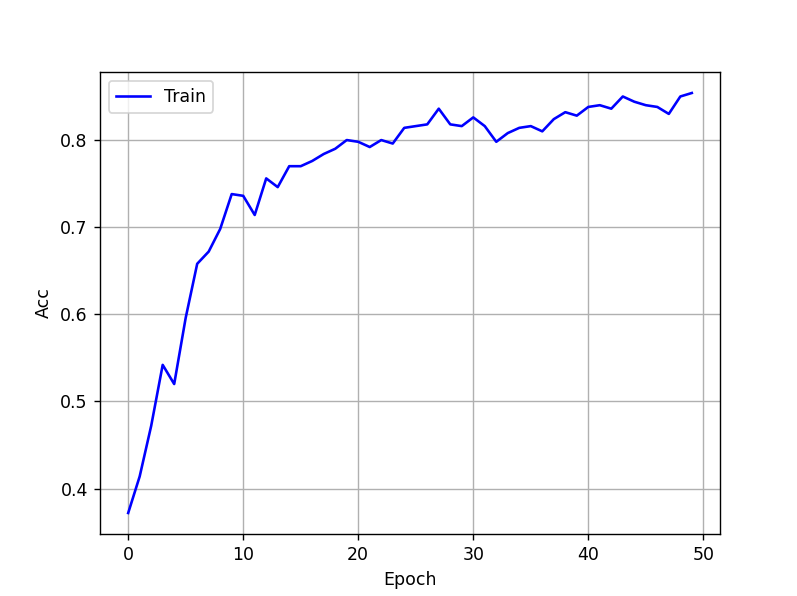
Avec 50 époques, on obtient ce graphe avec la fonction d'activation ELU :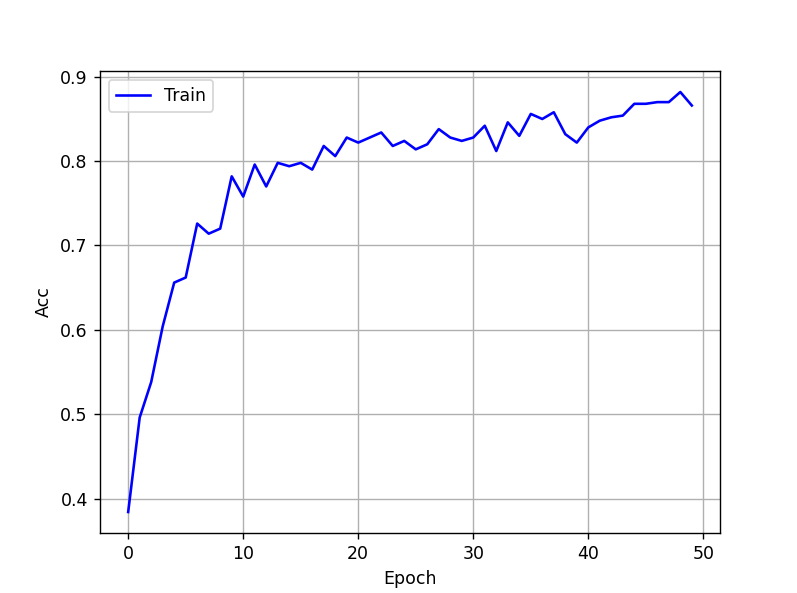
Avec quelques ajustements ci dessous :
fs= 173 #sampling frequency
channel= 8 #number of electrode (8 au lieu de 22 dans le script EEGNet et au lieu de 1 que j'avais mis)
num_input= 1 #number of channel picture (for EEG signal is always : 1)
num_class= 5 #number of classes
signal_length = 512 #number of sample in each tarial (512 au lieu de 200 dans le script EEGNet et au lieu de 4076 que j'avais mis)On obtient ces résultats : 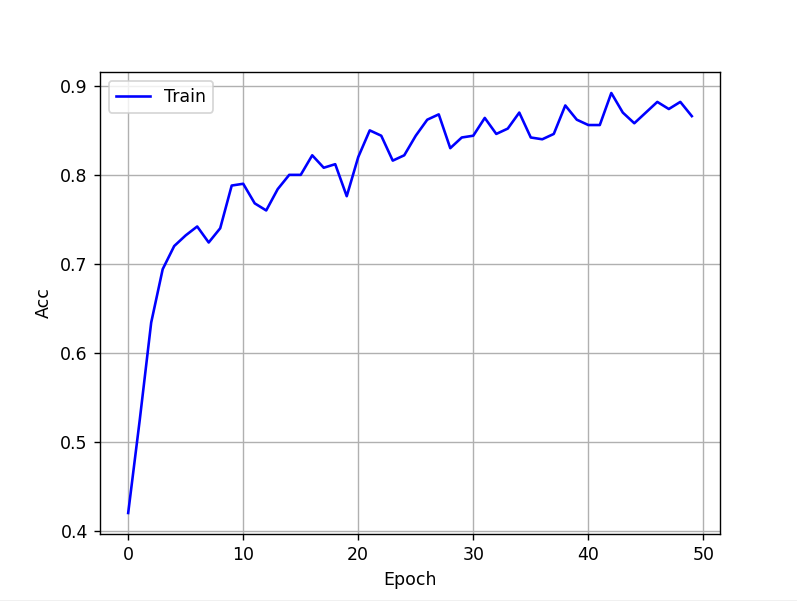
- 80% entraînement
- 10% validation
- 10% test
Il fallait séparer les données dans les 3 sous-dossiers du dossier dataclean (train, test, val), mais nous avons rencontré cette erreur :
ModuleNotFoundError: No module named 'splitfolders'
J'ai lancé VSCode via Anaconda, puis installé la dernière version e pip avec cette commande :
py -m pip install --upgrade pipEt en installant split-folders au lieu de splitfolders, avec la commande comme ci-dessous, mon code fonctionne.
py -m pip install split-foldersUne chose que j'ai aussi changé dans mon code est splitfolders.ratio au lieu de split.ratio.
Par la suite, nous avons enlevé backward(), optimizer.step() et optimizer.zero_grad(), qui sont incorrects pour la validation car cela modifie le modèle pendant la validation. On obtient pour la loss :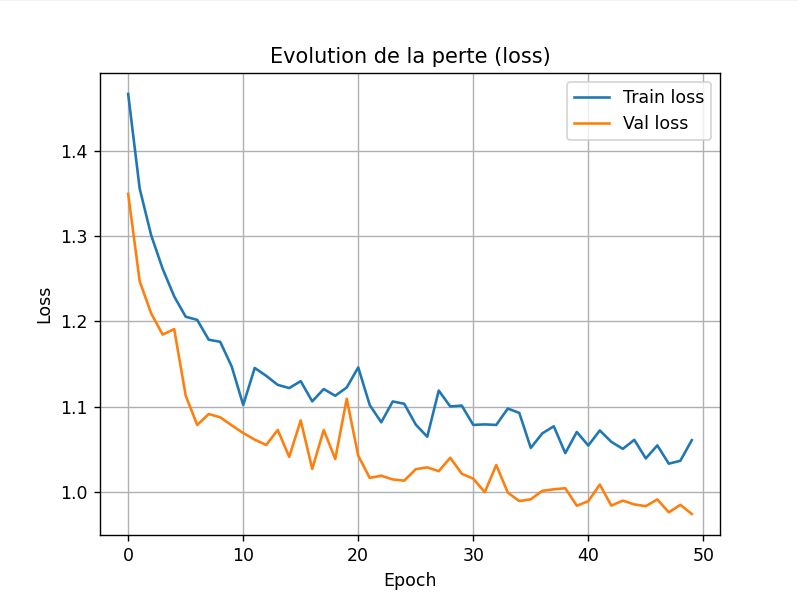
Et pour l'acc : 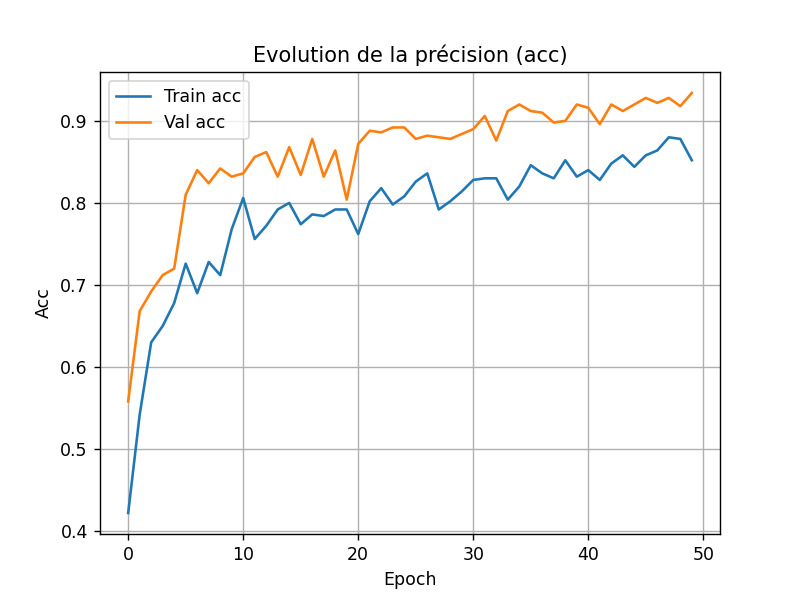
On a essayé de modifier le dropout avec Jhodi. D'abord à 0.05 ; bon apprentissage et sans surapprentissage, puis 0.5 ; moins bon apprentissage, enfin 0 ; bon apprentissage et les courbes de val et de train se confondent presque vers la fin de l'apprentissage (que ce soit en perte ou en précision).
On décide donc de rester avec un dropout_rate = 0.
On voulait ensuite mettre les données dans un fichier csv pour les stocker et éviter d'attendre trop longtemps lors de l'apprentissage et de l'évaluation de la performance du modèle.
J'aimerais bien aussi rajouter un code qui puisse enregistrer automatiquement les graphes dans un dossier avec le bon titre (informations en plus que je peux mettre dans les annexes du mémoire).
On a aussi parlé du problème du jeu de données. Celui sur les 5 classes correspondants à des patients neurotypiques ou neuroatypiques avec les yeux ouverts ou fermés est trop petit. On a que 500 fichiers de données au total, donc 80 pour l'entraînement de chaque classe et 20 pour la validation et le test de chaque classe. Le problème de la courbe de val_acc au dessus de train_acc vient peut-être de là. C'est-à-dire que la validation ne se fait que sur 10 fichiers comparé à 80 pour l'entraînement, donc l'apprentissage est sûrement meilleur pour seulement 10 fichiers comparé à 80 fichiers.
Il faudrait donc un plus gros jeu de données. En sachant que celui des vignes qu'on a déjà, les données ne sont pas labellisées donc inexploitables, qu'on a toujours pas réussi à capter les signaux de la plante grâce au capteur vegetal signals. D'ailleurs on a essayé l'ancien boitier, qui est certes plus dur à utiliser, mais qui nous permettrait peut-être juste de récupérer un jeu de données sur des plantes dans le fablab, exposées au soleil et à l'ombre, jours et nuits, durant tout le weekend. On a donc pensé à créer un jeu de données synthétique, mais cela nous prendrait trop de temps.
Donc autant attendre de voir si les capteurs récupèrent les signaux ou prendre carrément un autre jeu de données sur internet (qui se rapprocherait de données EEG ou de signaux).
Après l'acquisition des données de la plante, nous avons convertis les données en numpy, donc cela va rendre les fichiers de données brutes deux à trois fois plus lourds mais ils seront plus lisibles, toujours codés en binaire et c'est la façon la plus naturelle de les visualiser sous avec Python.
Jhodi a corrigé le code data_loader pour se baser sur les données de la plante au lieu des données kaggle. Pour améliorer la capacité de calcul, il a aussi intégrer de l'encodage one-hot. J'ai plus qu'à lancer le script toute la nuit pour observer les résultats (les graphiques).
On a aussi modifié un peu le script model.py, en modifiant la fonction elu dans la dernière couche du modèle en fonction Sigmoid, et le script traindata.py en modifiant "multitask" par "binary" dans les fonctions train_one_epoch et validation, puisque nous n'avons plus que 2 classes (day et night).
Voici ce que renvoie le script après l'avoir fait tourné toute cette nuit :
train batch size: 32 , num of batch: 2472
Inputs shape: torch.Size([32, 1, 8, 512])
Targets shape: torch.Size([32, 2])
epoch 0:
train loss= 0.3019, val loss=4.016, train acc= 86%, val acc= 58%
epoch 5:
train loss= 0.1173, val loss=37.23, train acc= 95%, val acc= 58%
epoch 10:
train loss= 0.09094, val loss=14.21, train acc= 96%, val acc= 61%
epoch 15:
train loss= 0.07863, val loss=13.95, train acc= 97%, val acc= 63%
epoch 20:
train loss= 0.05666, val loss=1.678, train acc= 98%, val acc= 73%
epoch 25:
train loss= 0.04815, val loss=2.347, train acc= 98%, val acc= 72%
epoch 30:
train loss= 0.05645, val loss=2.48, train acc= 98%, val acc= 65%
epoch 35:
train loss= 0.04723, val loss=1.254, train acc= 98%, val acc= 69%
epoch 40:
train loss= 0.04403, val loss=2.993, train acc= 98%, val acc= 91%
epoch 45:
train loss= 0.04048, val loss=1.076, train acc= 98%, val acc= 82%Il n'y a pas de graphiques car j'ai oublié de les décommenter.
On ne comprend pas pourquoi le modèle à une très bonne précision mais sans l'étape de pré-traitement des données (et sans l'étape de normalisation). Une hypothèse qui permettrait d'expliquer cela réside dans les couches du modèle, car dans plusieurs couches il se sert de Batch_normalization.
Voici les résultats qu'on obtient sur le jeu de données du 7 mai : 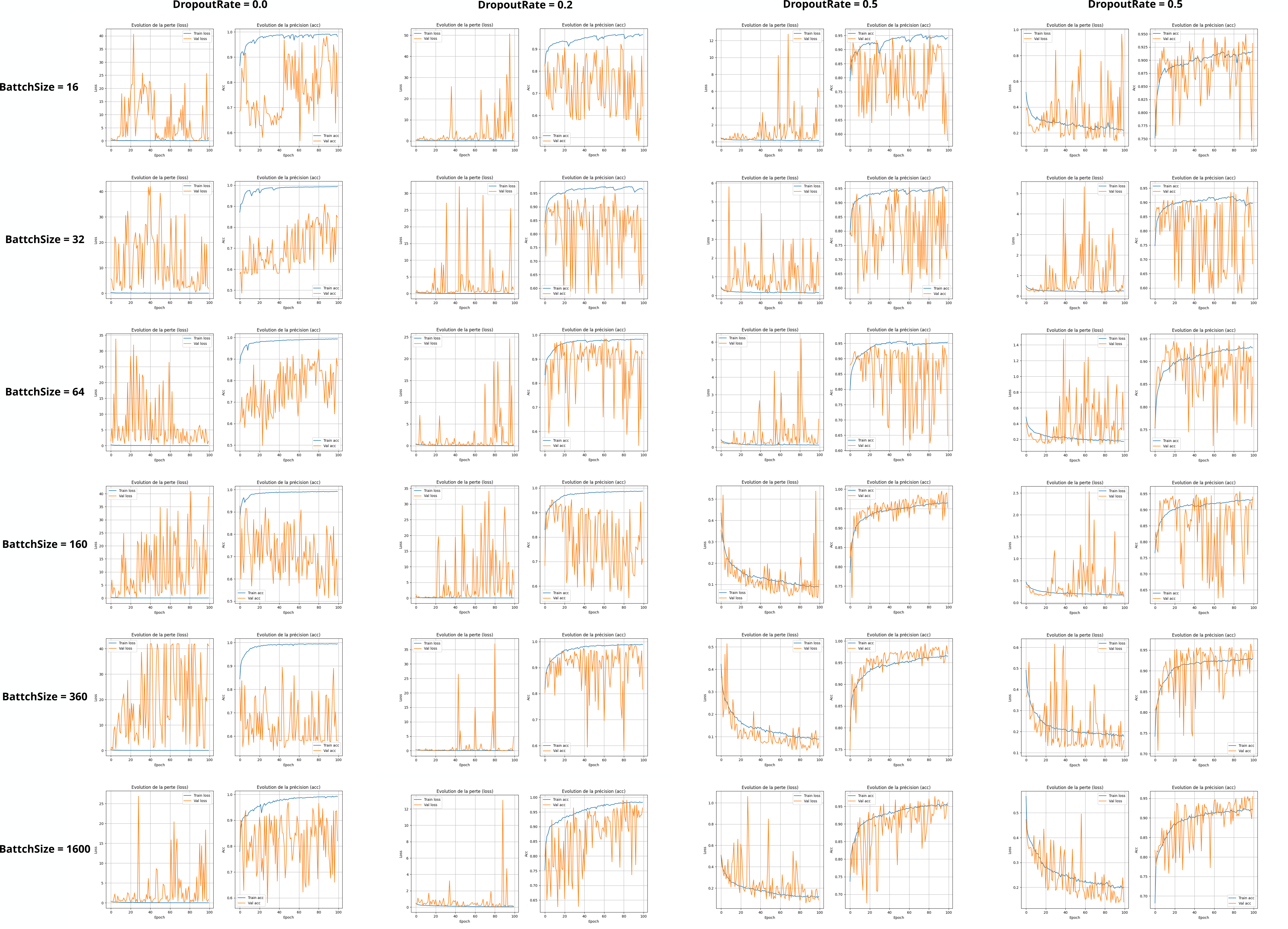
On observe un meilleur apprentissage pour un batchsize entre 160 et 360 et un dropout_rate de 0.5.
Pour l'apprentissage sur toutes les données, voici ce que l'on obtient : 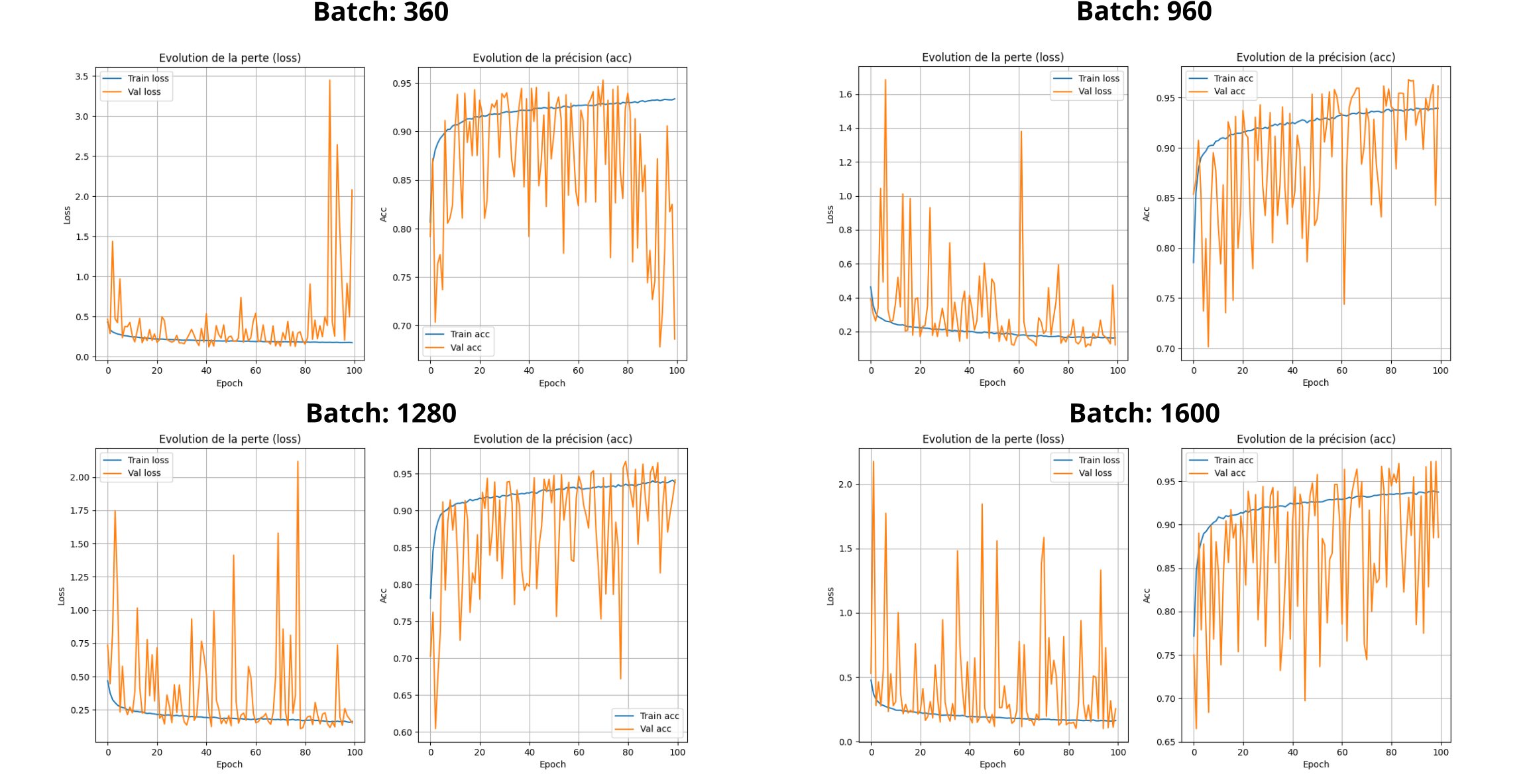
On constate un apprentissage trop erratique pour être généralisable.
Les choses à faire à l'avenir sur cette partie¶
Il faudrait tester plus de combinaisons d'hyperaramètres et tester d'autres filtres ou bien ne pas en appliquer du tout pour avoir une meilleure performance du modèle. Ensuite, il faudrait calculer la matrice de confusion, avec en ordonnées les données du modèle (y = dir(test)) et en abscisses les données prédites (y_pred = model(donnees)). Puis faire les calculs des scores avec scikit-learn (présenter les calculs sous la forme d'un tableau avec les scores (précision, recall et f1) en lignes et les classes en colonnes).
J'aimerais bien aussi rajouter un code qui puisse enregistrer automatiquement les graphes dans un dossier avec comme titre les hyperparamètres et la date.
Le code¶
Tous les scripts sont présents sur mon compte GitLab.
Partie électrophysiologie végétale¶
Nous avons opté pour une acquisition directement dans une carte SD car nous manquions de documentation sur le fonctionnement des capteurs et comment communiquer en USB ou à distance. Le boîtier des capteurs est alimenté par quatre piles 2A de 5 volts.
Nous avons rencontrés un problème avec Jhodi et Ludovic pour récupérer les signaux enregistrés par le capteur vegetal signals. Il semblerait y avoir un soucis avec la carte SD car rien ne s'affiche après l'enregistrement des signaux. Nous avons d'abord pensé aux 20 minutes après la pose des capteurs, qui représente la période d'adaptation à la plante suite à l'implantation des capteurs, et qui représente donc une période de mesure inutilisable. Mais après avoir attendu presque 1h, le résultat est le même; pas d'enregistrement dans la carte SD.
ON A DE LA DONNEE ! Lors de notre premier enregistrement, le 7 mai 2026 à 16h23, les piles se sont vidées au bout de 45 heures. Ce premier jeu de données est constitué de 45 940 échantillons de 512 mesures, soit environ 2 secondes d’enregistrement, répartis entre le jour et la nuit. Pour résoudre le problème de la batterie des piles, nous avons donc décidé de brancher le capteur sur secteur, en modifiant nous
mêmes le câble d’alimentation du capteur. J'ai donc fait de l'électronique ! Pierre m'a montré comment sertir, puis Ludovic m'a montré comment souder pour que nous puissions brancher le capteur vegetal signals en secteur au lieu d'utiliser des piles. On a aussi utilisé un multimètre pour vérifier le bon voltage qui sortait du câble assemblé.
Nous avons aussi détecté dès le début si les piles étaient en série ou en parallèle pour savoir si les volts des piles s'additionnaient ou non.
On a finalement 16h de données d'enregistrées. Les données brutes font 1,1 Go, en csv elles font un peu plus (2 Go et quelques) et converties en Numpy elles font 10 Go et quelques.
Lors du deuxième enregistrement, le 13 mai 2026 à 17h20, 122 heures d’enregistrements ont été récoltées, ce qui correspond à 289 942 échantillons de
512 mesures. Nous avons donc un premier jeu de données correspondant aux enregistrements du 7 mai 2026 et un deuxième jeu de données correspondant aux enregistrements du 13 mai 2026.
On a récupéré les données enregistrées tout le weekend mais les fichiers sont tous d'une taille différente. Jhodi voudrait donc utiliser un parser (qui permet d'analyser une chaîne de caractères et la convertir en une structure de données interprétable) avant de convertir le fichiers en tensor. Sauf que les données sont en binaire, donc il demandera à Ludovic comment faire quand ils seront tous les deux présents.
Pour voir plus de détails sur les figures et l'analyse statistique, voir le wiki de Jhodi
Les choses à faire à l'avenir sur cette partie¶
Refaire l'expérience en extérieur pour s'éloigner du réseau électrique et utiliser les capteurs témoins pour les mettre juste dans l'air (au lieu de les mettre dans la terre) afin de s'en servir pour la normalisation des données. Refaire l'expérience sur une plante et pas deux Monstera Deliciosa comme vu ici.
Ou bien parler d'un partenariat avec Bordeaux sciences agro pour faire l'expérience sur différentes plantes dans un environnement idéal (dans des serres).
Essayer de comprendre à quoi correspondent les amplitudes des signaux des plantes (via de la biblio ou des chercheurs).
Pour en savoir plus¶
Voici mon mémoire si vous voulez en savoir plus : https://projets.cohabit.fr/attachments/20773
Bibliographie¶
Andrzejak, R. G., Lehnertz, K., Mormann, F., Rieke, C., David, P., & Elger, C. E. (2001). Indications of nonlinear deterministic and finite-dimensional structures in time series of brain electrical activity: Dependence on recording region and brain state. Physical Review E, 64(6), 061907. DOI: 10.1103/PhysRevE.64.061907
Hofo, A. (2024). EEGNet Pytorch.ipynb [Code source]. GitHub. https://github.com/Amir-Hofo/EEGNet/blob/main/EEG-Net%20Pytorch.ipynb
Lawhern, V. J., Solon, A. J., Waytowich, N. R., Gordon, S. M., Hung, C. P., & Lance, B. J. (2018). EEGNet : A compact convolutional neural network for EEG-based brain–computer interfaces. Journal of Neural Engineering, 15(5), 056013. https://doi.org/10.1088/1741-2552/aace8c
Nguyen, B. Q. (2025). EEG Dataset [Jeu de données]. Kaggle. https://www.kaggle.com/datasets/quands/eeg-dataset