Arthur Tétaz¶
Plan général - J1
Le but est de reprendre le projet Plantes connectées. Pour cela, nous nous focaliserons sur ces différentes étapes :¶
1- Capter les signaux¶
Grâce au capteur Capteur_Vegetal_signals, nous allons utiliser 4 capteurs pour une plante qui serait au soleil et 4 capteurs pour une plante qui serait à l'ombre (ou bien carrément prendre 4 plantes et mettre 2 capteurs sur chacune). Au début, nous préférons simplifier les choses en faisant l'expérience avec du soleil en extérieur et mettre une plante dans une boîte pour la priver du soleil.
2- Visualiser les signaux en temps réel¶
Cette étape est pédagogique. Nous pouvons utiliser le logiciel Chataigne pour visualiser en temps réel les signaux des plantes.
3- Traiter les signaux¶
Il faut séparer cette étape en deux : d'abord acquérir les signaux des plantes puis les traiter ensuite. Nous avons vu en premier lieu les données de Quentin Perret, mais il semble à ce jour qu'il y a un problème avec la transformée de Fourier (TDF) car elle affiche seulement un pic à 0.
4- Entraîner les données¶
Tout d'abord, il faut réfléchir à l'architecture du modèle d'IA qui serait le plus adapté (modèle U-Net, random forest ou bien des réseaux de convolution type CNN). Ensuite choisir le bon framework entre PyTorch, Keras et TersorFlow (même si nous sommes plus partis sur PyTorch pour son aspect open source). Enfin, analyser le signal en Deeplearning. C'est-à-dire quelles méthodes peut-on utiliser et quelles sont les pipeline qui sont utilisées.
Note : ne pas oublier l'étape de normalisation dans le traitement.
5- Faire bouger le robot¶
Puisque le robot chenille n'est pas fonctionnel pour le moment, il faut d'abord se focaliser sur le robot axial, qui fait tourner le pot sur un seul axe. Pour ensuite, pourquoi pas, utiliser un plateau roulant ou un robot avec roue holonome (qu'on emprunterait à Rhoban) à utiliser en extérieur ou dans le Fablab.
6- Faire une interface utilisateur¶
Pour finaliser le projet et le présenter.
Au vu de mes 2 mois de stage, je me préoccuperais en particulier du traitement du signal ainsi que l'entraînement des données.
J2¶
Nous avons rencontrés un problème avec Jhodi et Ludovic pour récupérer les signaux enregistrés par le capteur vegetal signals. Il semblerait y avoir un soucis avec la carte SD car rien ne s'affiche après l'enregistrement des signaux. Nous avons d'abord pensé aux 20 minutes après la pose des capteurs, qui représente la période d'adaptation à la plante suite à l'implantation des capteurs, et qui représente donc une période de mesure inutilisable. Mais après avoir attendu presque 1h, le résultat est le même; pas d'enregistrement dans la carte SD.
Pour de ce qui est de la partie d'entraînement des données, je commence à me familiariser avec la consctruction d'un réseau de neurone convolutif. En me basant sur le code de cet article, et en utilisant des données plus concrètes trouvées sur kaggle plutôt que les données aléatoires créées dans la partie training de l'article, j'essaie de comprendre comment ces modèles fonctionnent pour ensuite les utiliser sur les données récoltés des plantes (afin de savoir si le modèle repère si les plantes sont à l'ombre ou bien au soleil).
J3¶
Télétravail (TT).
Même boulot que J2 sur la création d'un réseau de neurone convolutif.
J4¶
Je dois faire une biblio de tous les articles regardés (en commençant par l'article de com racinaire, puis les articles utilisés pour le réseau de neurone).
Détails pour les données EEG-Data de kaggle :- O et Z = set A et B, respectivement les mesures yeux ouverts et jeux fermés pour des individus neurotypiques
- F et N = set C et D, respectivement les mesures des zones épileptogènes pendant une période sans crise et prélevées dans l'hippocampe de l’hémisphère opposé chez les patients épileptiques
- S = set E, mesures d'une crise épileptique chez les patients épileptiques.
Je pense partir sur des bibliothèques Python que j'ai déjà vu telles que Keras et TensorFlow. Nous étions partis de base sur PyTorch, car le gros point fort de cet librairie est qu'elle est open source, mais après avoir mis les mains dans le cambouis je me suis rendu compte que je n'y comprenais pas grand chose. Donc grâce à ce site et à mes connaissances passées en deeplearning avec la fac, je pense utiliser TensorFlow et Keras (qui est intégrée à TensorFlow) pour construire mes réseaux de neurones et entraîner mes modèles sur les données récupérées sur les plantes.
J'ai l'impression de vouloir avancer sans comprendre les notions de base en informatique (programmation orientée objet, construire son environnement virtuel et passer par un venv...)
J5¶
Aujourd'hui c'était full deeplearning. On a travailler en PyTorch avec Jhodi et on a bien avancé. On a une bonne base de données d'entrainements avec les données kaggle et le script EEGNet. On a notamment repris la partie du script qu'on avait laissé sur la création de données aléatoire pour faire la transformation en tensor. La transformation permet de nettoyer (en enlevant le bruit), de normaliser (mettre tout sur la même échelle) et mettre en forme (adapter le signal à l'architecture).
Nous avons donc créer le modèle, fait la partie training et load (charger les données), mis les data en les mettant dans des listes puis mis les listes dans le même format que celles créées de façon random pour le modèle EEGNet.
Manque plus qu'à les entraîner pour voir si notre modèle construit fonctionne bien pour ensuite l'entraîner sur les données des plantes.
J8¶
Voici l'article qui a prouvé que les racines de plantes communiquées entre elles : https://www.sciencedirect.com/science/article/abs/pii/S1567539419301914 / DOI : 10.1016/j.bioelechem.2019.05.003 (sinon le pdf entier sur sci-bub).
Aujourd'hui, nous continuons sur la construction du réseau de neurones avec Jhodi. Nous avons rencontré plusieurs problèmes tels que celui ci :
RuntimeError: mat1 and mat2 shapes cannot be multiplied (16x2880 and 3072x5)En premier lieu nous avons pensé que cette erreur était due à la fonction d'activation utilisée dans les couches denses (hidden layers) du réseau. J'ai donc changé la fonction ELU par Tanh mais rien ne changeait. L'autre possibilité venait de cette ligne dans le script du modèle EEGNet :
self.Dense = nn.Linear(F2*round(signal_length/32), num_class)Ca fonctionne bien, le modèle s'entraîne ! Avec 50 époques, on obtient ce graphe avec la fonction d'activation Tanh :
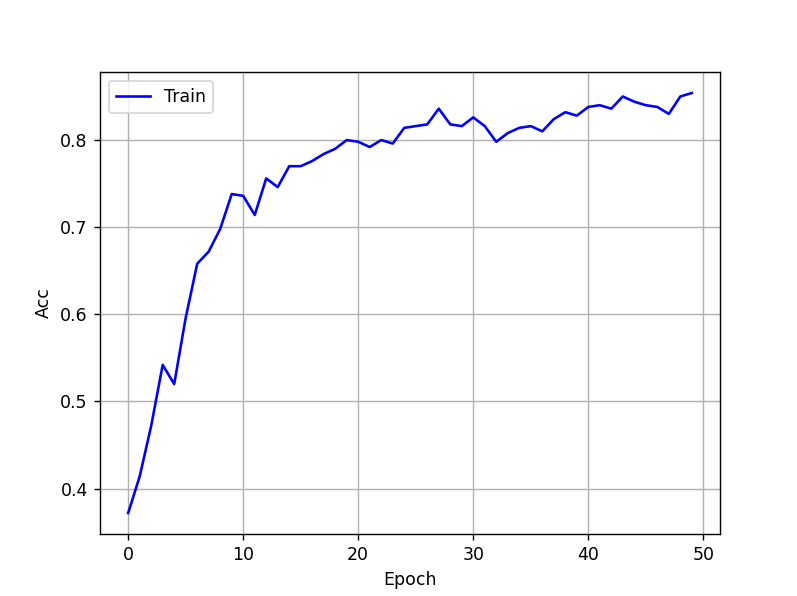
Avec 50 époques, on obtient ce graphe avec la fonction d'activation ELU :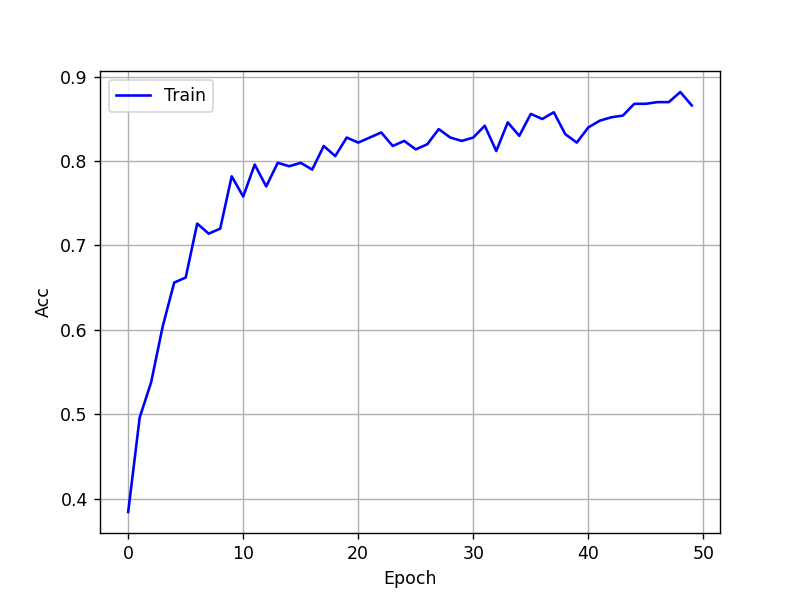
Avec les quelques ajustements ci-dessous,
fs= 173 #sampling frequency
channel= 8 #number of electrode (8 au lieu de 22 dans le script EEGNet et au lieu de 1 que j'avais mis)
num_input= 1 #number of channel picture (for EEG signal is always : 1)
num_class= 5 #number of classes
signal_length = 512 #number of sample in each tarial (512 au lieu de 200 dans le script EEGNet et au lieu de 4076 que j'avais mis)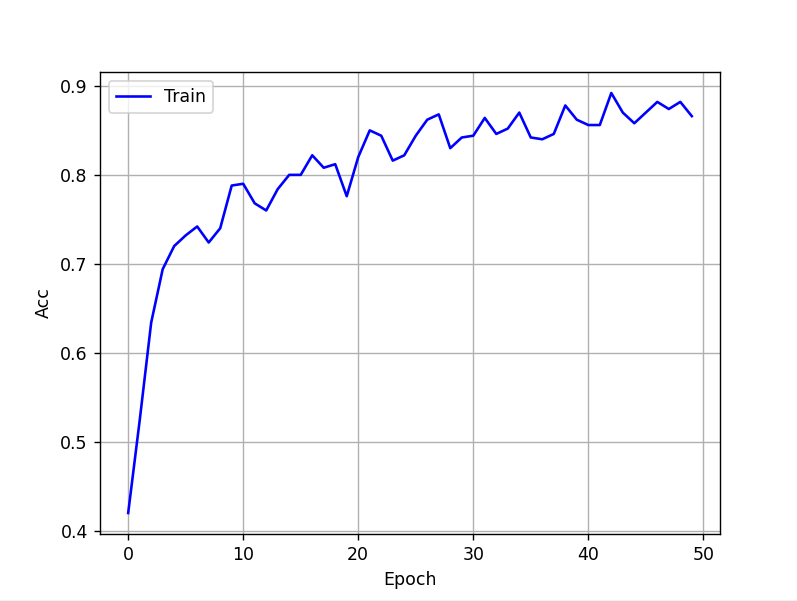
J9¶
TT.J'ai commencé à faire la fonction validation pour pouvoir afficher la différence de précision et de perte entre les données d'entraînement et de validation. Comme nous nous sommes basés sur le dataset de base (sans avoir à séparer les données dans des dossiers distincts pour l'entraînement, la validation et le test), je devrais, par la suite, séparer les données en 3 dossiers :
- 80% entraînement
- 10% validation
- 10% test
Ensuite, il faudra faire la matrice de confusion puis, enfin, faire le calcul des scores (précision, recall et F1).
J10¶
Voici ce que j'obtiens pour la perte du modèle pour l'apprentissage des données :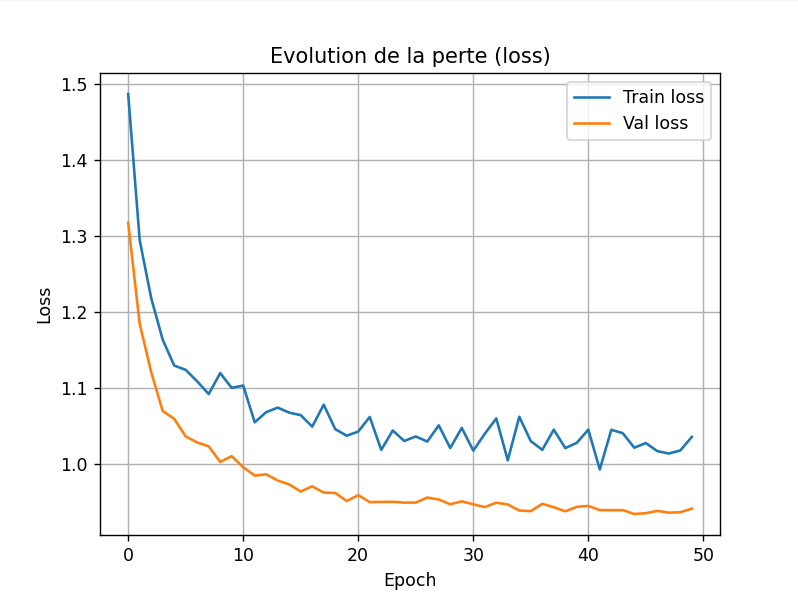
Et pour la précision :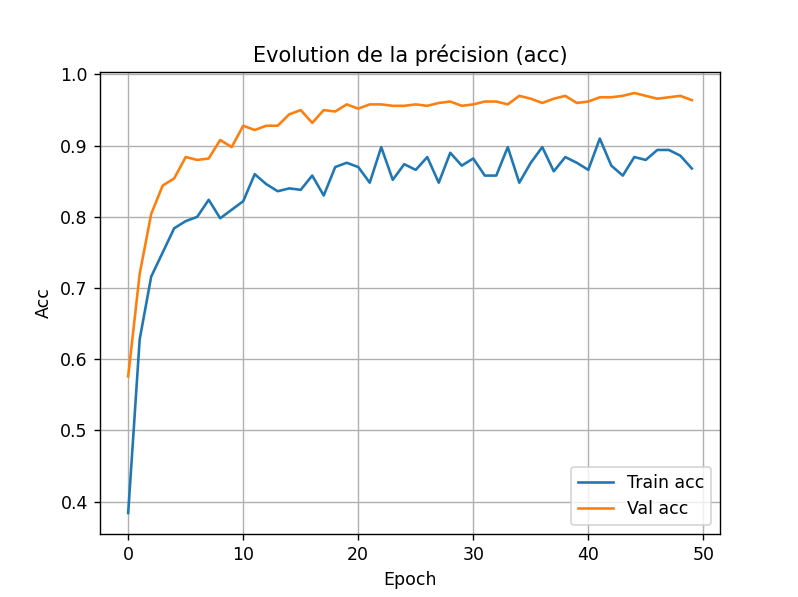
Remarque : la validation est plus haute que l'entraînement. La plupart du temps c'est l'inverse.
Avec cette réponse du script :
500
500
torch.Size([500, 1, 8, 512])
train batch size: 16 , num of batch: 32
epoch 0:
train loss= 1.486, val loss=1.317,train acc= 38%, val acc= 57%
epoch 5:
train loss= 1.123, val loss=1.036,train acc= 79%, val acc= 88%
epoch 10:
train loss= 1.103, val loss=0.9952,train acc= 82%, val acc= 92%
epoch 15:
train loss= 1.064, val loss=0.9632,train acc= 83%, val acc= 94%
epoch 20:
train loss= 1.042, val loss=0.9585,train acc= 87%, val acc= 95%
epoch 25:
train loss= 1.036, val loss=0.9487,train acc= 86%, val acc= 95%
epoch 30:
train loss= 1.017, val loss=0.9464,train acc= 88%, val acc= 95%
epoch 35:
train loss= 1.03, val loss=0.9375,train acc= 87%, val acc= 96%
epoch 40:
train loss= 1.045, val loss=0.9443,train acc= 86%, val acc= 96%
epoch 45:
train loss= 1.027, val loss=0.9347,train acc= 87%, val acc= 97% J11¶
TT.
Lecture du wiki de Ludovic et j'ai commencé à regarder comment séparer les données en fichiers train, test et val avec les nouvelles données.
J15¶
J'ai commencé la rédaction, ou plutôt le plan, de mon rapport/mémoire et je suis toujours sur la séparation des données en 3 fichiers.
J16¶
J'ai réussi à séparer les données dans les 3 sous-dossiers du dossier dataclean, après avoir résolu l'erreur suivante :
ModuleNotFoundError: No module named 'splitfolders'
J'ai lancé VSCode via Anaconda, puis installé la dernière version de pip avec cette commande :
py -m pip install --upgrade pipEt en installant split-folders au lieu de splitfolders, avec la commande comme ci-dessous, mon code fonctionne.
py -m pip install split-foldersUne chose que j'ai aussi changé dans mon code est splitfolders.ratio au lieu de split.ratio.
L'étape suivante est donc la matrice de confusion ainsi que le calcul des scores (que je verrais demain avec Jhodi).
J17¶
Construction de la matrice de confusion. En ordonnées les données du modèle (y = dir(test)) et en abscisses les données prédites (y_pred = model(donnees)). Puis faire les calculs des scores avec scikit-learn (présenter les calculs sous la forme d'un tableau avec les scores en lignes et les classes en colonnes).
Je dois faire le ménage dans mes scripts et mes fichiers (notamment inspi et datasettransform) pour mieux comprendre chaque code et pouvoir intégrer le code test et ainsi faire la matrice de confusion.
En enlevant backward(), optimizer.step() et optimizer.zero_grad(), qui sont incorrects pour la validation car cela modifie le modèle pendant la validation, j'obtiens pour la loss : 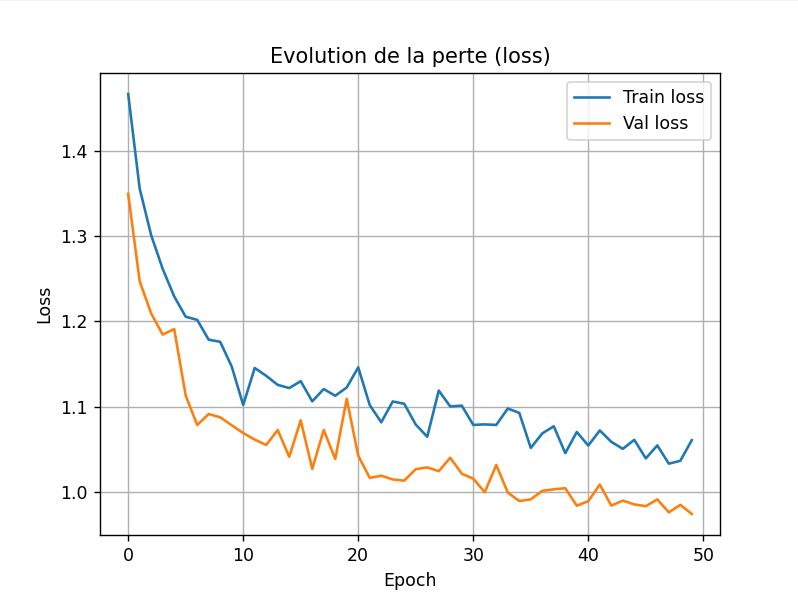
Pour l'acc : 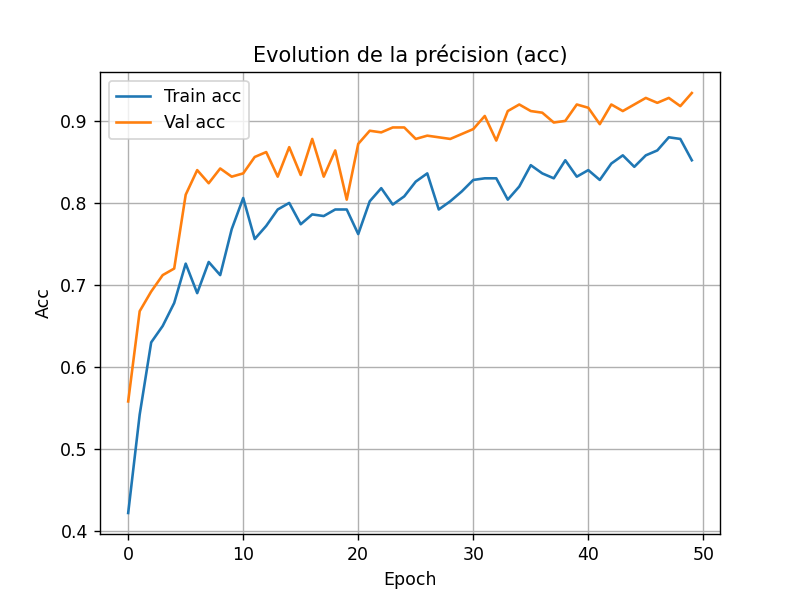
Note pour plus tard : changer le dropout_rate de 0.2 à 0.8 ou 0.9 pour voir si le modèle a moins de surapprentissage (et voir si les courbes s'inverse pour l'acc).
J18¶
On a essayé de modifier le dropout avec Jhodi. D'abord à 0.05 ; bon apprentissage et sans surapprentissage, puis 0.5 ; moins bon apprentissage, enfin 0 ; bon apprentissage et les courbes de val et de train se confondent presque vers la fin de l'apprentissage (que ce soit en perte ou en précision).
On décide donc de rester avec un dropout = 0.
On voulait ensuite mettre les données dans un fichier csv pour les stocker et éviter d'attendre trop longtemps lors de l'apprentissage et de l'évaluation de la performance du modèle.
J'aimerais bien aussi rajouter un code qui puisse enregistrer automatiquement les graphes dans un dossier avec le bon titre (informations en plus que je peux mettre dans les annexes du mémoire).
On a aussi parlé du problème du jeu de données. Celui sur les 5 classes correspondants à des patients neurotypiques ou neuroatypiques avec les yeux ouverts ou fermés est trop petit. On a que 500 fichiers de données au total, donc 80 pour l'entraînement de chaque classe et 20 pour la validation et le test de chaque classe. Le problème de la courbe de val_acc au dessus de train_acc vient peut-être de là. C'est-à-dire que la validation ne se fait que sur 10 fichiers comparé à 80 pour l'entraînement, donc l'apprentissage est sûrement meilleur pour seulement 10 fichiers comparé à 80 fichiers.
Il faudrait donc un plus gros jeu de données. En sachant que celui des vignes qu'on a déjà, les données ne sont pas labellisées donc inexploitables, qu'on a toujours pas réussi à capter les signaux de la plante grâce au capteur vegetal signals. D'ailleurs on a essayé l'ancien boitier, qui est certes plus dur à utiliser, mais qui nous permettrait peut-être juste de récupérer un jeu de données sur des plantes dans le fablab, exposées au soleil et à l'ombre, jours et nuits, durant tout le weekend. On a donc pensé à créer un jeu de données synthétique, mais cela nous prendrait trop de temps.
Donc autant attendre de voir si les capteurs récupèrent les signaux ou prendre carrément un autre jeu de données sur internet (qui se rapprocherait de données EEG ou de signaux).
- essayer le cross validation pour voir si le problème de la courbe de val au dessus de celle de train s'inverse pour la précision du modèle
- faire pleins de parallèles entre homme et plantes (EEG/capteurs, classification yeux ouverts yeux fermés/plantes au soleil ou à l'ombre...)
- étoffer la bibliographie en mettant des articles sur le modèle CNN, sur la communication des plantes et la collecte des données de ses dernières via des capteurs. Pour les refs/tutos de programmation ce sera dans la webographie
- commencer le mémoire en notant des idées (sans rentrer dans les détails et sans faire ni l'introduction ni la conclusion que je ferrais à la fin)
ON A DE LA DONNEE ! L'ancien capteur enregistre des signaux. Donc on va le laisser tourner tout le weekend (de 3 jours) pour pouvoir entraîner le modèle dessus.
J22¶
Aujourd'hui je commence la bilbio en cherchant et lisant des articles qui pourrait être intéressant pour présenter le contexte du projet ou en répondant à ces questions :- Comment les plantes communiquent entre elles → article sur tomate et aloe vera
- Quels sont les environnements favorables pour une communication et une évolution des plantes saines ?
- Comment récupérer, traiter et analyser ces signaux ?
- Comment un CNN fonctionne ? Quel modèle d’apprentissage serait le plus adapté dans notre cas (entraîner sur un jeu de données de signaux)
Pour l'instant j'ai fait le résumé de cet article et j'ai commencé avec celui là.
Je vais continuer à faire ça durant les prochains jours.
Les données du capteur n'ont enregistré que 5200 secondes d'enregistrement, donc ça n'a pas tenu le weekend de trois jours. C'est sûrement lié aux piles car le capteur ne s'allume plus. Il faudrait donc essayer de brancher le capteur sur secteur et réessayer.
J23¶
Je continue sur la biblio.
J'ai fait de l'électronique aujourd'hui ! Pierre m'a montré comment sertir, puis Ludovic m'a montré comment souder pour que nous puissions brancher le capteur vegetal signals en secteur au lieu d'utiliser des piles. On a aussi utilisé un multimètre pour vérifier le bon voltage qui sortait du câble assemblé.
Nous avons aussi détecté dès le début si les piles étaient en série ou en parallèle pour savoir si les volts des piles s'additionnaient ou non.
J24¶
On a finalement 16h de données d'enregistrées. Les données brutes font 1,1 Go, en csv elles font un peu plus (2 Go et quelques) et converties en Numpy elles font 10 Go et quelques.
Avec Jhodi on m'a créé mon compte GitLab. J'ai pu mettre mes codes sur le site ainsi qu'un README.
Lancement du capteur à 16h24 le 13/05/2026, on va le laisser enregistrer tout le weekend (4 jours) puis on va pouvoir commencer à entrainer le modèle dessus. D'ici là il faut que je fiche au moins un article de classification de signaux avec le CNN et re-entraîner un peu le modèle avec les données que j'ai (en enregistrant automatiquement les graphes à chaque entraînement).
J29¶
On a récupéré les données enregistrées tout le weekend mais les fichiers sont tous d'une taille différente. Jhodi voudrait donc utiliser un parser (qui permet d'analyser une chaîne de caractères et la convertir en une structure de données interprétable) avant de convertir le fichiers en tensor. Sauf que les données sont en binaire, donc il demandera à Ludovic comment faire quand ils seront tous les deux présents.
De mon côté, je continue la biblio, en particulier sur cet article qui traite la classification de sons environnementaux par un modèle CNN.
On va convertir les données en numpy, donc cela va rendre les fichiers de données brutes deux à trois fois plus lourds mais ils seront plus lisibles, toujours codés en binaire et c'est la façon la plus naturelle de les visualiser sous avec Python.
J30¶
J'ai continué sur la biblio et j'ai commencé la rédaction de mon mémoire (notamment la partie Contexte du stage et Analyse de l'objectif du stage).
Dès que j'avancerais un peu plus sur la rédaction du mémoire, je pourrais en faire part à Pierre. Et je pourrais même lui faire des petits entraînements pour la soutenance, afin de voir les problèmes à régler.
J31¶
Problématique du rapport/mémoire : est ce qu'un modèle de détection électrophysiologique humain (EEG) peut aussi servir pour la détection électrophysiologique des plantes.
Parler des limites rencontrées, aussi celles du hardware.
Jhodi a corrigé le code data_loader pour se baser sur les données de la plante au lieu des données kaggle. Pour améliorer la capacité de calcul, il a aussi intégrer de l'encodage one-hot. J'ai plus qu'à lancer le script toute la nuit pour observer les résultats (les graphiques).
J'ai avancé sur mon mémoire, j'ai envoyé une première version à Pierre et Jhodi pour voir si la structure est bonne et que les idées proposées sont aussi bonnes.
Bibliographie¶
Communication des plantes¶
Les modèles¶
Webographie¶
Quel(s) modèle(s) ?¶
Construction du modèle¶
PyTorch¶